Text Summarization for Research Papers
Table of Contents
- Text Summarization for Research Papers
- What Exactly is Text Mining (and Why Does it Matter)?
- The Core Battle: Extractive vs. Abstractive Summarization
- 1. Extractive Summarization
- 2. Abstractive Summarization
- Building the Platform: The Developer’s Blueprint
- 1. The Frontend (The User Experience)
- 2. The Backend (The Engine Room)
- 3. The Preprocessing Pipeline
- The Technical Hurdles: It’s Not All Sunshine and Rainbows
- The 2026 Edge: Multimodal and Explainable AI
- Summary Table: Tech Stack Comparison
- Conclusion: Making Science Scalable
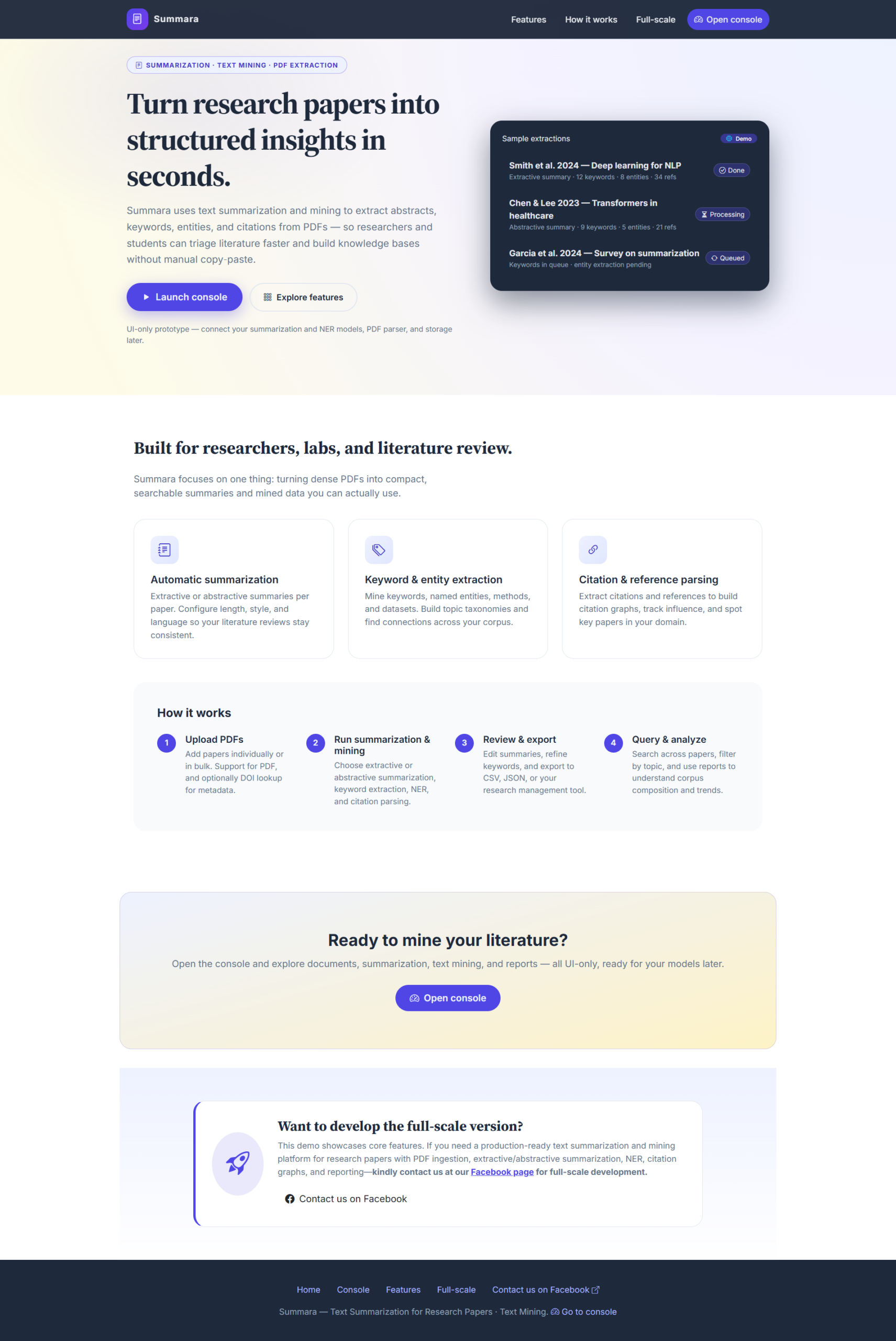
If you’ve ever spent a Saturday night with 42 open tabs, each containing a 30-page PDF on “Quantum Cryptography” or “The Sociological Impact of Micro-Influencers,” you know the feeling. Your eyes are glazed, your coffee is cold, and you’re no closer to understanding the actual thesis than you were three hours ago.
We are living in an era of “Information Obesity.” For researchers, students, and developers, the bottleneck isn’t finding information—it’s processing it. This is where Text Mining and Natural Language Processing (NLP) step in, not just as academic buzzwords, but as the foundation for a life-saving online platform: The Automated Research Summarizer.
In this post, we’re going to look at the “how” and “why” of developing such a platform, moving past the hype to look at the actual development architecture.
What Exactly is Text Mining (and Why Does it Matter)?
Text Mining is essentially the process of transforming “unstructured” text (the messy, human way we write) into “structured” data that a machine can actually do something with. When we apply this to research papers, we aren’t just looking for keywords. We’re looking for intent, relationships, and significance.
Think of it like this: If a search engine is a librarian who tells you which shelf the book is on, a Text Mining platform is the genius friend who reads the whole shelf and tells you exactly which three sentences matter.
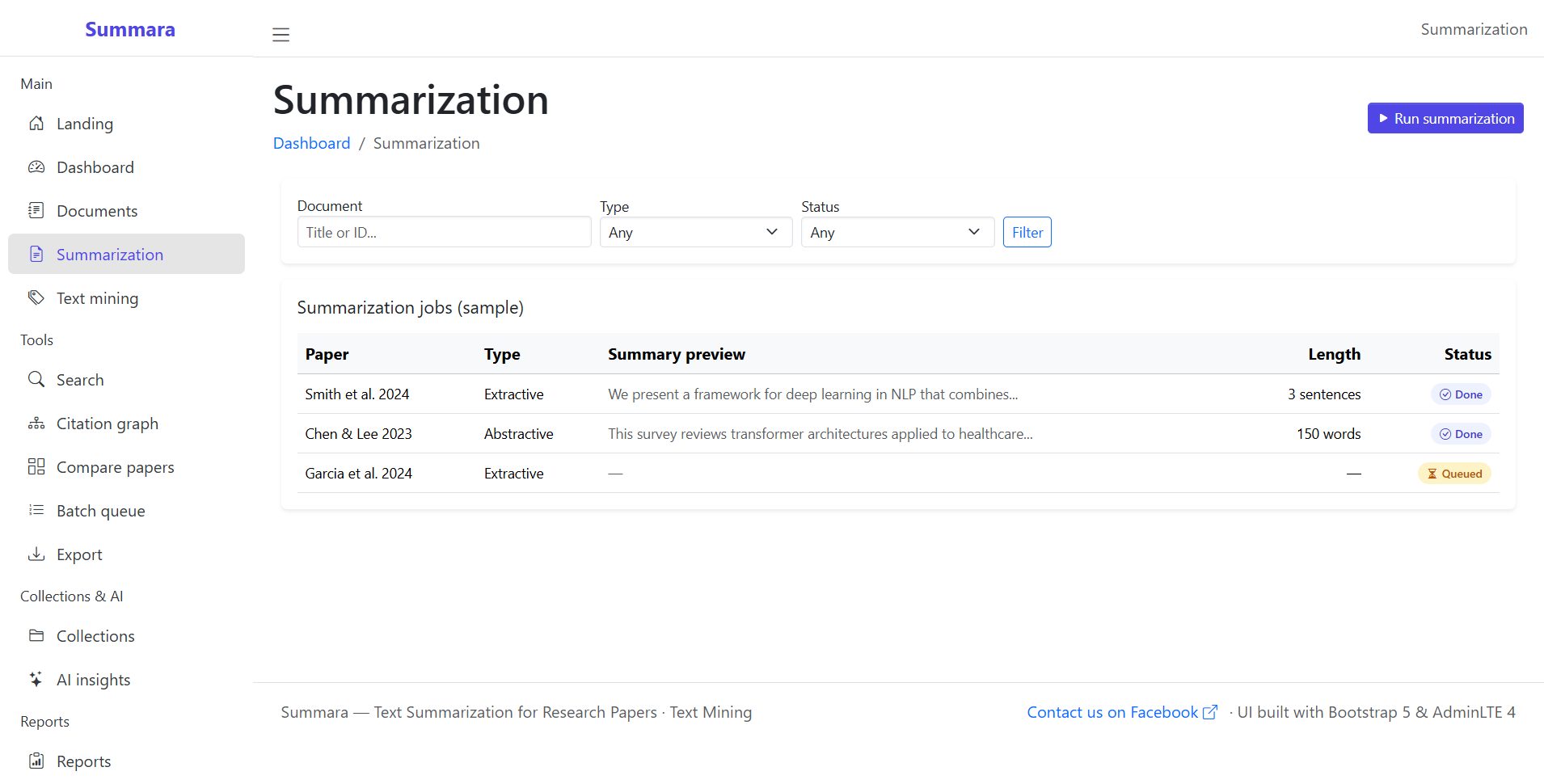
The Core Battle: Extractive vs. Abstractive Summarization
When you start developing your platform, you’ll hit a fork in the road. There are two primary ways to summarize text, and choosing the right one (or a hybrid) is the most important technical decision you’ll make.
1. Extractive Summarization
This is the “Highlighter Approach.” The algorithm identifies the most important sentences already present in the paper and stitches them together. It’s reliable, computationally cheap, and keeps the original context.
-
Top Algorithms: LexRank, TextRank, and RAKE.
-
Pros: Fast, no “hallucinations” (the AI making stuff up).
-
Cons: Can feel disjointed; it doesn’t “write” a summary, it “finds” one.
2. Abstractive Summarization
This is the “Human Approach.” The AI reads the entire text, understands it, and then writes a completely new summary in its own words. It’s more fluid and natural, but much harder to build.
-
Top Models (2026): Fine-tuned T5, PEGASUS, and Llama-3-Instruct.
-
Pros: Coherent, readable, and captures the “essence.”
-
Cons: Resource-heavy; requires significant GPU power for real-time applications.
Building the Platform: The Developer’s Blueprint
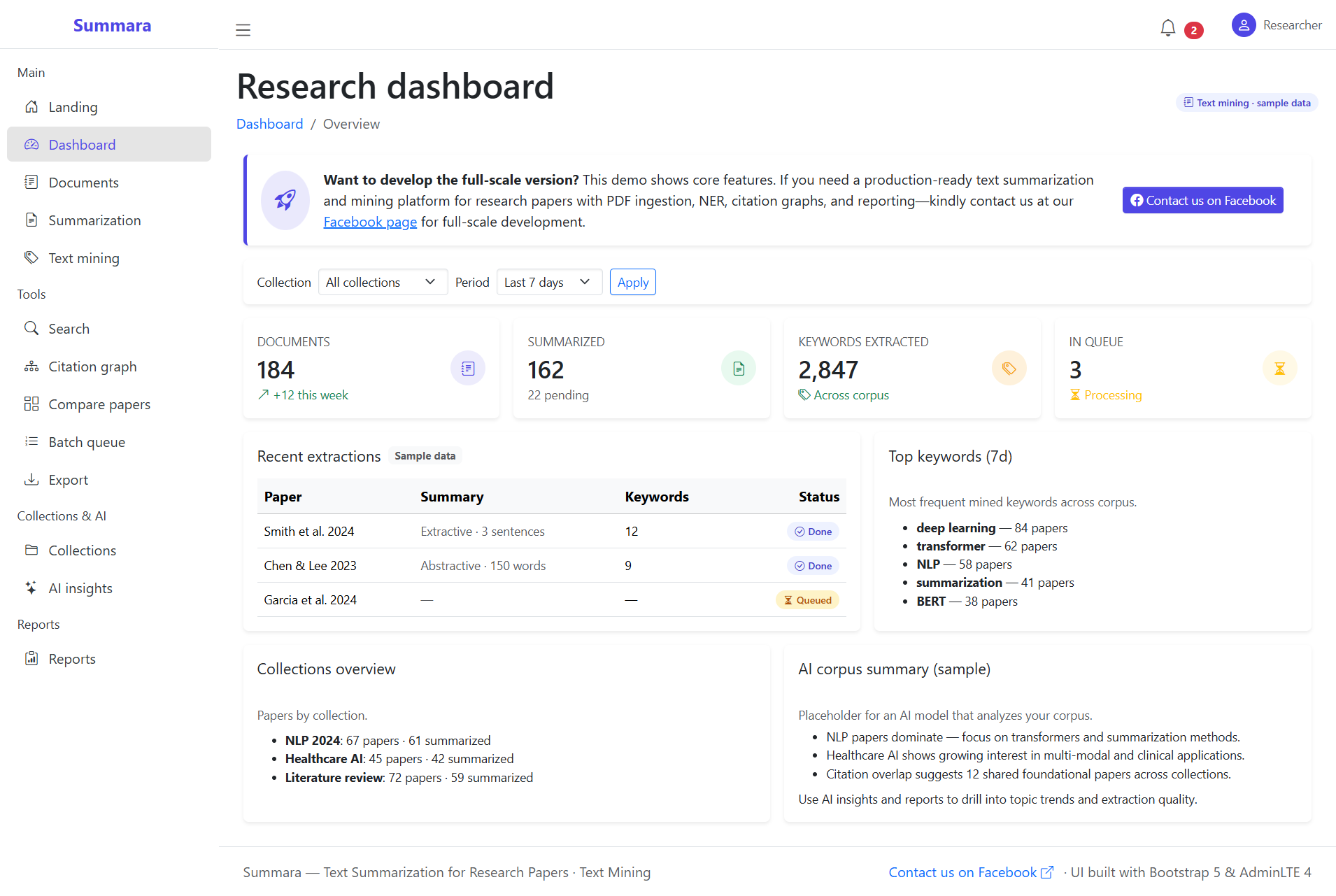
Developing an online platform for this isn’t just about the AI model; it’s about the pipeline. You need a robust system that can handle a messy PDF and turn it into a clean, summarized dashboard.
1. The Frontend (The User Experience)
Don’t overcomplicate this. Researchers want a “drop-and-go” interface.
-
Stack: React.js or Next.js for a fast, responsive UI.
-
Key Feature: A side-by-side view where the original PDF stays on the left, and the AI-generated summary (with clickable citations) appears on the right.
2. The Backend (The Engine Room)
This is where the heavy lifting happens.
-
Stack: FastAPI (Python). It’s asynchronous, incredibly fast, and has native support for data validation—perfect for handling heavy ML tasks.
-
Database: PostgreSQL for user data and Elasticsearch for indexing the papers so users can search through their own library of summaries.
3. The Preprocessing Pipeline
You can’t just feed a raw PDF into a Transformer model.
-
PDF Parsing: Use libraries like
PyPDF2orGrobid(specifically for scientific papers) to handle multi-column layouts and extract text without losing the headings. -
Cleaning: Use SpaCy or NLTK to remove noise (headers, footers, page numbers) and perform tokenization.
-
Vectorization: Convert the text into numbers (embeddings) using models like BERT or RoBERTa.
The Technical Hurdles: It’s Not All Sunshine and Rainbows
If building this were easy, everyone would have one. As a developer, you’re going to run into a few “brick wall” moments:
-
The Math Problem: Research papers are full of equations ($E=mc^2$). Most NLP models treat these as gibberish. You’ll need a preprocessing step that identifies LaTeX or math blocks and preserves them.
-
The Length Problem: Standard Transformers have a “context window” (limit on how much text they can read at once). For a 50-page thesis, you’ll need to implement Longformer or a “Map-Reduce” approach—summarizing chunks and then summarizing the summaries.
-
Citation Handling: A summary that says “This study proves X” is useless unless it can link back to the specific paragraph in the source.
Developer Note: Always implement a “Confidence Score.” If the AI isn’t sure it summarized a section correctly, tell the user. Transparency beats “perfect” summaries every time.
The 2026 Edge: Multimodal and Explainable AI
We’re moving beyond just text. The next generation of these platforms includes:
-
Graph Mining: Visualizing how different papers are connected via their citations.
-
Multimodal Input: Summarizing the charts and graphs within a paper alongside the text.
-
Explainable AI (XAI): Highlighting exactly which sentences in the source led to a specific point in the summary.
Summary Table: Tech Stack Comparison
| Component | Recommended Tool | Why? |
| Language | Python | The undisputed king of AI/ML libraries. |
| API Framework | FastAPI | High performance, async-ready. |
| NLP Library | SpaCy | Production-grade speed and reliability. |
| Summarization | Hugging Face Transformers | Access to SOTA models like BART/T5. |
| PDF Extraction | Grobid | Specifically designed for scientific metadata. |
| Frontend | Next.js | Excellent for SEO and fast loading. |
Conclusion: Making Science Scalable
Building an online platform for research paper summarization isn’t just an IT project; it’s a productivity revolution. By leveraging Text Mining, we can bridge the gap between the staggering volume of new knowledge and our limited human bandwidth.
Whether you’re building a tool for your university or a commercial SaaS product, the goal is the same: Let the humans do the thinking, and let the machines do the reading.
You may visit our Facebook page for more information, inquiries, and comments. Please subscribe also to our YouTube Channel to receive free capstone projects resources and computer programming tutorials.
Hire our team to do the project.