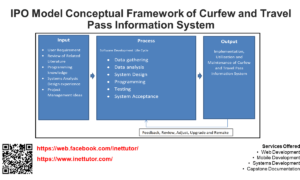
Title: Beyond the Red Pen: Building an Automated Essay Grading System with Text Mining
Picture this: It’s 11 PM on a Sunday. A high school English teacher sits at their kitchen table, surrounded by what looks like a scaled-down architectural model of Stonehenge made entirely of paper. They are essays on To Kill a Mockingbird. The teacher is on page three of the fiftieth essay, their eyes are blurring, and the red pen is running dry.
This scenario is the reality for educators worldwide. Grading is necessary, but it’s also exhaustive, repetitive, and notoriously difficult to scale.
As developers, whenever we see “exhaustive, repetitive, and difficult to scale,” our ears perk up. That sounds like a job for automation.
A few months ago, our team decided to tackle this classic EdTech challenge. We set out to build an online platform—an Automated Essay Grading System (AEGS)—powered by text mining and Natural Language Processing (NLP). We weren’t trying to build Robo-Teacher; we wanted to build a hyper-efficient assistant that could handle the heavy lifting of initial assessment.
It’s been a fascinating, frustrating, and incredibly revealing development journey. Here is an under-the-hood look at how we’re using text mining to turn paragraphs into grades, and the hard lessons we learned along the way.
The “Why”: More Than Just Saving Time
Table of Contents
- The “Why”: More Than Just Saving Time
- De-mystifying the Magic: What is Text Mining Anyway?
- The Development Pipeline: Building the Engine
- 1. The Preprocessing (The Janitorial Work)
- 2. Feature Extraction (Finding What Matters)
- 3. The Model (The Virtual Grader)
- The “Human Touch” Dilemma: Where It Fails
- The Platform Perspective
- Conclusion: A Partnership, Not a Replacement
Before diving into the code, we had to define the philosophy of the platform. Why build this?
If you talk to teachers, the biggest bottleneck in improving student writing isn’t instruction; it’s feedback loops. A student writes an essay, hands it in, and waits three weeks to get it back. By then, they’ve forgotten what they wrote. They look at the grade, maybe glance at the comments, and stuff it in their backpack. Learning opportunity: missed.
Our goal for this platform was instant feedback. We wanted a student to submit a draft at 2 AM and get immediate insights on their grammar, structure, and thematic coherence. This allows them to iterate before the final human review.
We needed to build a system that didn’t just spit out a “B-“; it needed to explain why.
De-mystifying the Magic: What is Text Mining Anyway?
When we tell people we are using text mining to grade essays, they usually imagine an AI turning on a lightbulb and “understanding” Hemingway.
Let’s be honest: computers don’t understand squat. They don’t feel emotions when they read a poignant thesis statement. To a computer, an essay is just a very long, messy string of characters.
Text mining is the process of taking that messy unstructured text and beating it into structured data that algorithms can digest. It’s about turning qualitative words into quantitative metrics.
If regular data mining is like sifting through a neat Excel spreadsheet looking for patterns, text mining is like trying to find patterns in a dumpster full of shredded newspapers. You first have to tape the shreds back together, figure out which language they are in, remove the coffee stains, and then start looking for insights.
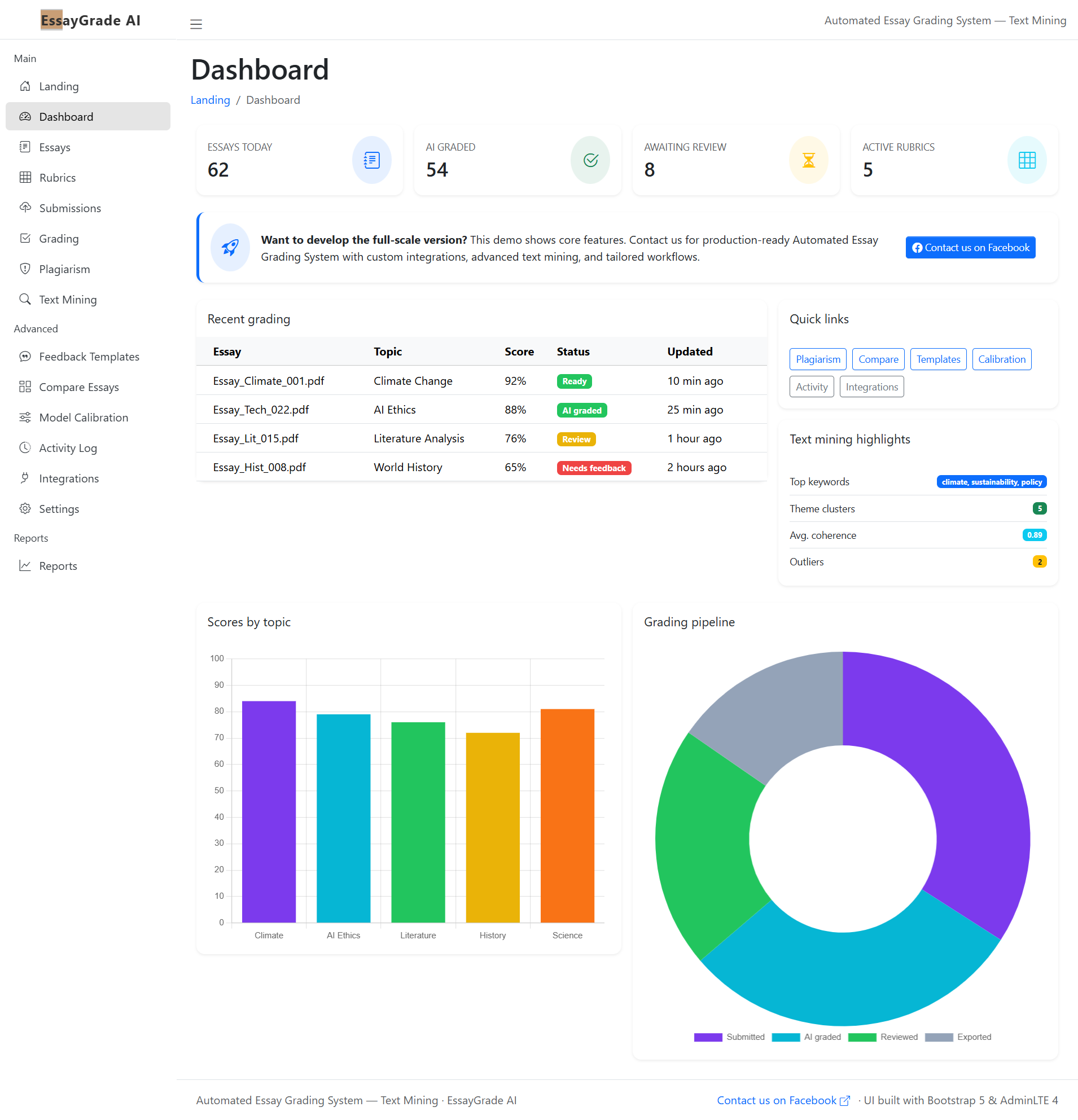
The Development Pipeline: Building the Engine
Building the backend for this platform was less about magic algorithms and more about setting up a rigorous assembly line for words. We leaned heavily on Python’s ecosystem (libraries like NLTK, spaCy, and scikit-learn are absolute lifesavers in this domain).
Here is what happens when a student hits “Submit” on our front-end:
1. The Preprocessing (The Janitorial Work)
The raw text of an essay is noisy. Before we can analyze it, we have to clean it. This is easily 60% of the work in any NLP project.
-
Tokenization: We break the essay down from paragraphs into sentences, and sentences into individual words (tokens).
-
Stop Word Removal: We strip out the common filler words that don’t add much semantic meaning—”the,” “is,” “at,” “which.” (Though, we found we had to be careful here; sometimes “not” is very important to the meaning of a sentence!)
-
Lemmatization: This is about standardizing words. “Running,” “ran,” and “runs” all get converted down to their base root: “run.” This helps the model see that these are all essentially the same concept.
2. Feature Extraction (Finding What Matters)
Once the text is clean, how do we determine quality? We can’t just feed words into a machine learning model. We need “features”—measurable characteristics of the writing.
We broke our features down into two categories: surface-level and deep-level.
The Surface-Level Stuff (Easy Win):
These are things a basic script could check.
-
Spelling and Grammar errors: (Using existing libraries).
-
Vocabulary richness: Are they repeating the same adjective five times in one paragraph? We use Type-Token Ratio (TTR) to measure lexical diversity.
-
Sentence length variation: Good writing usually has a mix of long flowing sentences and punchy short ones. A huge block of uniform sentence lengths is a red flag for readability.
The Deep-Level Stuff (The Hard Part):
This is where the real text mining comes in. How do we grade coherence or topic relevance?
-
Semantic Analysis (LSA/LDA): We used techniques like Latent Semantic Analysis to identify the underlying topics in an essay. If the prompt is about the Civil War, and the essay’s dominant mathematical topics relate to pizza toppings, we have a relevance problem.
-
Coherence Modeling: This was tricky. We had to analyze the transitions between sentences. Are they using connective words (however, therefore, furthermore)? Does sentence B logically follow sentence A? We ended up using entity-grid models to track how subjects shift throughout a paragraph. If the focus jumps around wildly, the coherence score drops.
3. The Model (The Virtual Grader)
Once we have extracted hundreds of these features for a single essay, we create a “feature vector”—basically a numerical fingerprint of the essay.
We then feed this into a supervised machine learning model. We trained our model on thousands of previously graded essays (anonymized, of course). The model learns correlations: “Hey, essays that have high vocabulary richness AND strong paragraph transitions usually get an A.”
We experimented with everything from simple Linear Regression to more complex Support Vector Machines (SVM) and Random Forests. We found Random Forests gave us a good balance of accuracy and interpretability—we needed to be able to work backward to explain why it gave a certain grade.
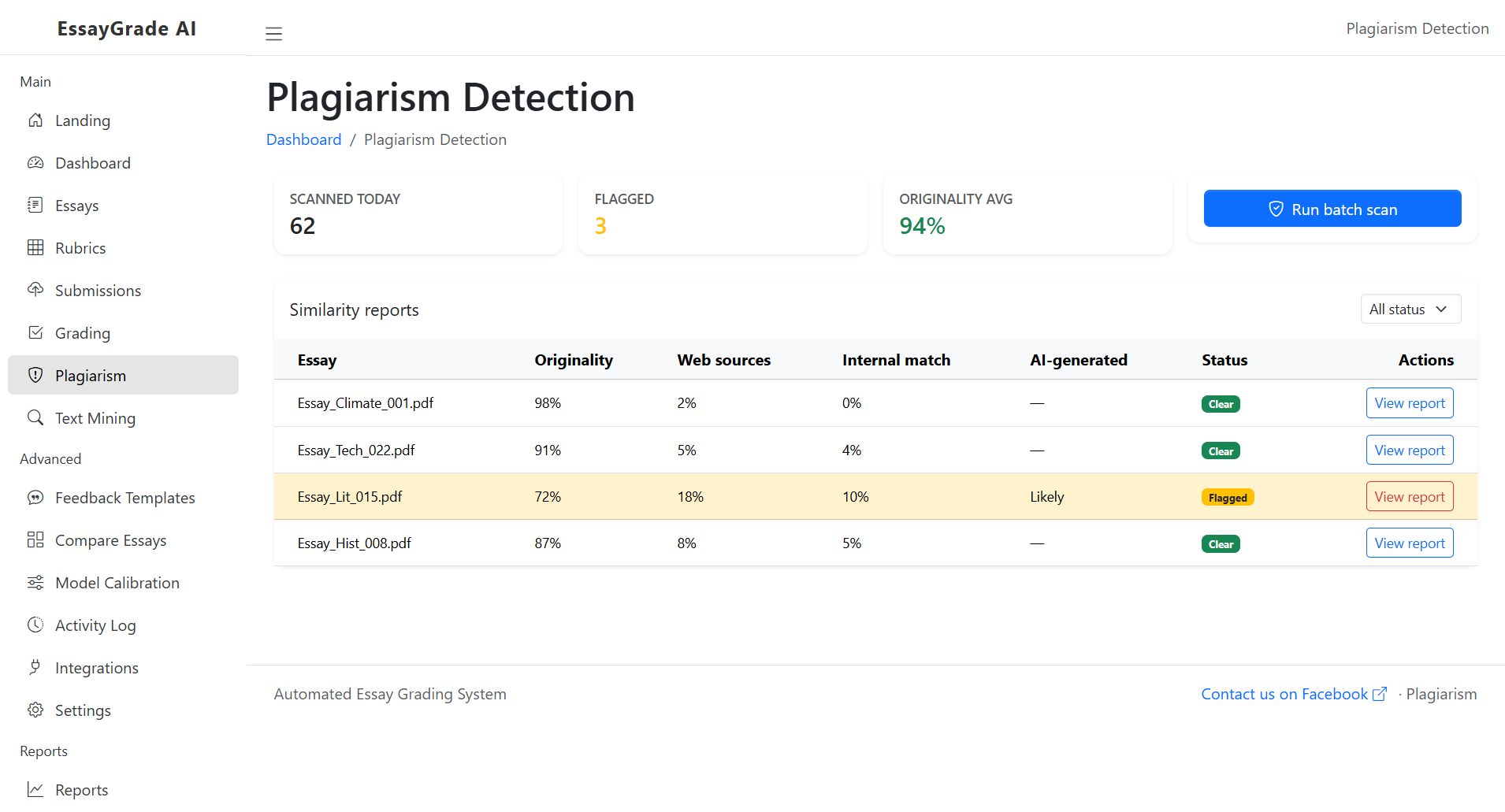
The “Human Touch” Dilemma: Where It Fails
I don’t want to paint a rosy picture where our system is perfect. It’s not. Throughout development, we constantly ran into the limitations of AI.
Frankly, AEGS struggles with creativity.
A student might write an incredibly unconventional, brilliant essay that breaks all the grammatical rules for stylistic effect. Our system would likely flag it as a disaster. It struggles with sarcasm, extended metaphors, and subtle nuance.
We also had to fight hard against bias. If the training data was graded by teachers who preferred a very rigid, academic style, the AI learns to penalize anything that sounds conversational. We spent weeks trying to “de-bias” our datasets to ensure fair grading across different writing styles.
The Platform Perspective
Building the engine was only half the battle. We needed a usable online platform.
We went with a modern stack—React on the front end for a snappy, responsive user experience, communicating via REST API with a Flask (Python) backend where the heavy NLP lifting happens.
The UX design was crucial. We didn’t want just a score. The interface highlights problematic sentences, offers suggestions for synonyms, and visualizes the essay structure. It needs to feel like a supportive coach, not a judgmental calculator.
Conclusion: A Partnership, Not a Replacement
After months of development, here is my major takeaway: The goal of automated essay grading isn’t to replace the teacher. It’s to augment them.
The best use case for the platform we are building is “triage.” Let the AI handle the formative assessment. Let it catch the grammar issues, the weak structures, and the spelling mistakes so the student can fix them on their own.
When the final essay lands on the teacher’s (physical or digital) desk, it’s already polished. The teacher can then spend their energy focused on the higher-order thinking, the argumentation, and the student’s unique voice—the things a computer will likely never truly understand.
We are turning text into data, yes. But ultimately, we’re doing it to give humanity a little more room to breathe in the classroom. And as a developer, that’s a pretty satisfying feature to ship.
You may visit our Facebook page for more information, inquiries, and comments. Please subscribe also to our YouTube Channel to receive free capstone projects resources and computer programming tutorials.
Hire our team to do the project.