Insurance Claim Processing Database Design
Introduction
Table of Contents
The Insurance Claim Processing System is a vital tool designed to streamline the complex process of handling insurance claims, ensuring efficiency, accuracy, and transparency for all stakeholders. In the real world, processing insurance claims—whether for health, auto, or property—can be slow and error-prone without a robust system. Delays in claim approvals, lost documents, or inconsistent data can frustrate policyholders and increase operational costs for insurance companies. This system solves these problems by automating claim tracking, validation, and approval workflows, providing a seamless experience from claim submission to payout.
The target users of this system include insurance companies, claims adjusters, policyholders, and third-party service providers like repair shops or medical facilities. For example, a policyholder filing a car accident claim can upload documents, track progress, and receive updates in real time. Adjusters can review claims, verify coverage, and approve payouts efficiently, while insurance companies benefit from reduced processing times and improved customer satisfaction. Regulatory bodies may also use the system to audit compliance with industry standards.
This blog post aims to guide readers through designing a database for the Insurance Claim Processing System. You’ll learn how to model a database that supports fast, secure, and scalable claim processing. We’ll explore the importance of a well-structured database, outline the planning process, detail the schema with tables and relationships, and provide SQL queries for practical operations. Whether you’re a developer building an insurance platform, a student working on a capstone project, or a business analyst exploring process optimization, this post offers a clear blueprint to create a robust database. Expect to dive into entity-relationship modeling, normalization techniques, and SQL implementations that ensure efficiency and reliability. By the end, you’ll have the tools to design a database that streamlines claims processing and enhances trust in the insurance ecosystem.
The database design process we’ll cover addresses challenges like managing high claim volumes, ensuring data security, and supporting compliance reporting. From defining entities like policies and claims to crafting queries for claim status reports, this post will equip you with practical insights to build a system that meets real-world needs. Let’s get started on designing a database that powers efficient insurance claim processing!
Importance and Benefits of Database Design
A well-designed database is the cornerstone of the Insurance Claim Processing System, enabling efficient, secure, and scalable operations. Without a robust database, the system would struggle to manage the complex data flows involved in processing claims, leading to delays, errors, and dissatisfied customers.
Data Integrity: Accurate data is critical for claims processing. For instance, linking a claim to the correct policy ensures payouts are valid. A poorly designed database risks inconsistencies, such as duplicate claims or mismatched policyholder details, which could lead to fraudulent payouts or disputes. By using primary and foreign keys, the database enforces relationships, ensuring claims align with valid policies and policyholders.
Scalability: Insurance companies handle thousands of claims daily, and the database must scale to accommodate growth. A well-structured schema, with indexed fields like claim IDs or policy numbers, supports rapid data retrieval even as the dataset grows. This ensures the system remains responsive during peak claim periods, such as after natural disasters.
Performance: Efficient database design optimizes operations like claim validation or status tracking. Without proper indexing or normalization, queries could slow down, delaying approvals and frustrating users. For example, an adjuster querying a claim’s history needs instant results. A streamlined schema minimizes query execution time, improving user experience.
Maintainability: The system must adapt to new requirements, such as updated compliance rules or new insurance products. A modular database, with clearly defined tables and relationships, simplifies updates without disrupting operations. This reduces maintenance costs and ensures long-term reliability.
Challenges Without Proper Design: Without a solid database, the system could face data redundancy, where policy or customer details are duplicated across tables, wasting storage and risking inconsistencies. For instance, duplicate customer records could lead to conflicting claim histories. Slow queries due to unnormalized data could delay claim approvals, harming customer trust. Security risks, such as unauthorized access to sensitive data like medical records or financial details, could arise without proper access controls enforced through the database.
By prioritizing database design, the Insurance Claim Processing System ensures efficient operations, avoids redundancy, supports growth, and provides secure, reliable access to data. This foundation enables fast claim processing, regulatory compliance, and a seamless experience for policyholders and adjusters.
Steps in Planning the Database
Designing a database for the Insurance Claim Processing System requires a structured approach to meet its unique needs. Below are the key steps, tailored to ensure efficiency and reliability in managing insurance claims.
Step 1: Requirement Analysis
Begin by gathering requirements from stakeholders—insurance companies, adjusters, policyholders, and regulators. The system must track claims, validate policies, manage documents, and generate compliance reports. For example, policyholders need real-time claim status updates, while regulators require audit trails. This step identifies functional needs (e.g., claim approval workflows) and non-functional needs (e.g., security and performance).
Step 2: Entity and Attribute Identification
Identify core entities and their attributes. For this system, entities include Policyholders, Policies, Claims, Adjusters, and Documents. Attributes for a Policyholder might include customer_id, name, and contact_info. Claims need attributes like claim_id, policy_id, and claim_amount. This ensures all necessary data points are captured for processing and tracking.
Step 3: Relationship Mapping
Define how entities relate. For example, a Policyholder has multiple Policies, and each Policy can have multiple Claims. A Claim is assigned to an Adjuster and may have multiple Documents. Mapping these relationships ensures the database reflects the real-world claim process. For instance, a foreign key in the Claims table links to the Policies table to validate coverage.
Step 4: Normalization
Normalize the database to eliminate redundancy and ensure data integrity. For example, store policyholder details in a separate table rather than repeating them in the Claims table. This reduces storage needs and simplifies updates, such as when a policyholder changes their contact information. Normalization also ensures accurate claim-policy linkages.
Step 5: Drafting an ER Diagram
Create an Entity-Relationship (ER) Diagram to visualize entities, attributes, and relationships. For this system, the ER diagram would show Policyholders linked to Policies, Policies linked to Claims, and Claims connected to Adjusters and Documents. This serves as a blueprint for developers and helps stakeholders validate the design.
Step 6: Validating with Stakeholders
Share the ER diagram and schema with stakeholders to ensure it meets their needs. For example, adjusters might confirm that the Claims table includes fields for status and comments, while regulators verify audit logging capabilities. Iterative feedback ensures the design supports real-world use cases like claim tracking and compliance.
By following these steps, the Insurance Claim Processing System’s database is tailored to manage claims efficiently, ensure data accuracy, and scale with demand. This structured approach creates a reliable foundation for the system.
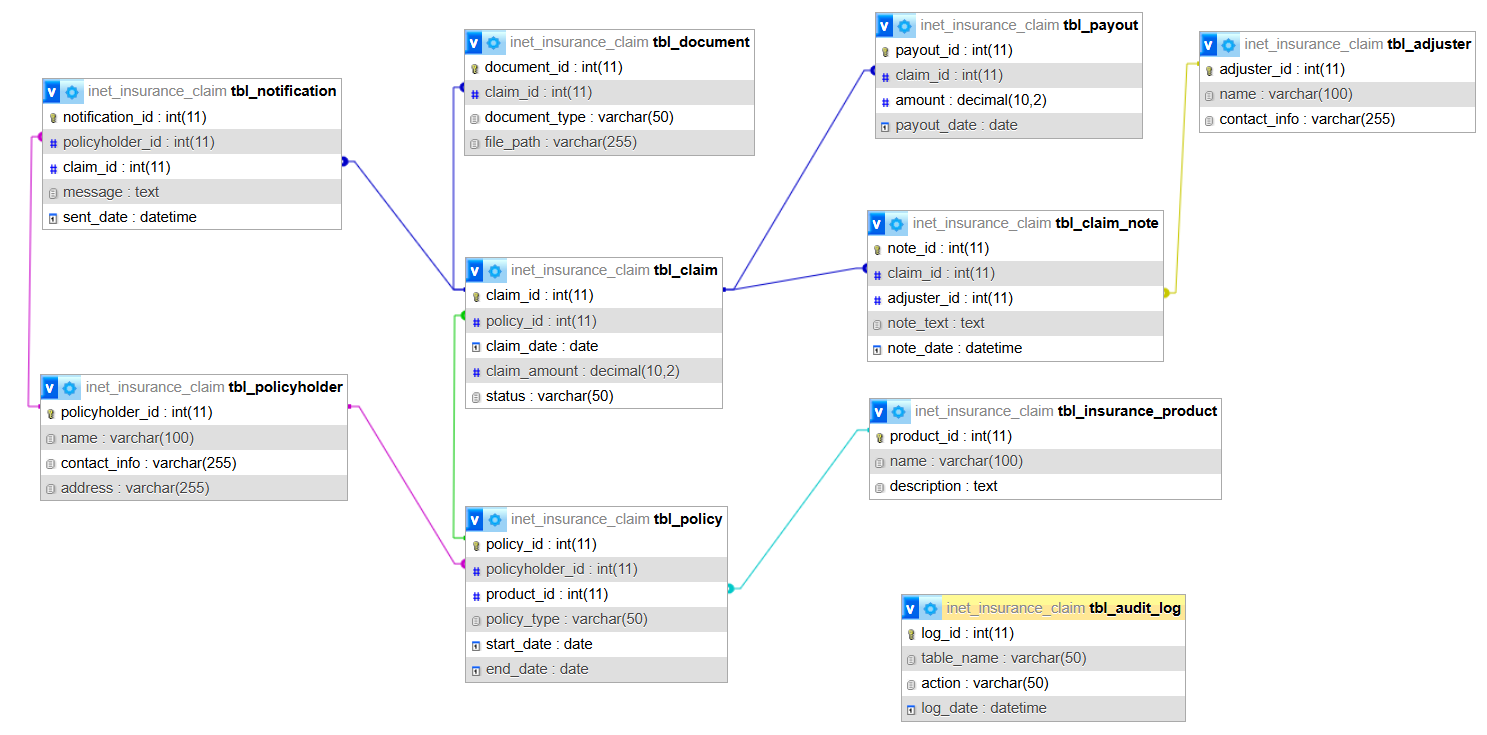
Database Design: List of Tables
The Insurance Claim Processing System requires a comprehensive database schema to manage claims efficiently. Below is a list of 10 key tables, each with a description, fields, primary and foreign keys, and relationships. SQL CREATE TABLE statements are provided to implement the schema.
tbl_policyholder
- Description: Stores details about policyholders (customers).
- Fields:
- policyholder_id (INT, Primary Key): Unique identifier.
- name (VARCHAR): Policyholder’s name.
- contact_info (VARCHAR): Email or phone.
- address (VARCHAR): Home address.
- Relationships: Links to tbl_policy (one policyholder has many policies).
tbl_policy
- Description: Stores insurance policy details.
- Fields:
- policy_id (INT, Primary Key): Unique policy identifier.
- policyholder_id (INT, Foreign Key): Links to tbl_policyholder.
- policy_type (VARCHAR): Type (e.g., auto, health).
- start_date (DATE): Policy start date.
- end_date (DATE): Policy end date.
- Relationships: Links to tbl_policyholder and tbl_claim.
tbl_claim
- Description: Tracks individual claims filed by policyholders.
- Fields:
- claim_id (INT, Primary Key): Unique claim identifier.
- policy_id (INT, Foreign Key): Links to tbl_policy.
- claim_date (DATE): Date filed.
- claim_amount (DECIMAL): Requested amount.
- status (VARCHAR): Status (e.g., pending, approved).
- Relationships: Links to tbl_policy, tbl_adjuster, and tbl_document.
tbl_adjuster
- Description: Stores details about claims adjusters.
- Fields:
- adjuster_id (INT, Primary Key): Unique identifier.
- name (VARCHAR): Adjuster’s name.
- contact_info (VARCHAR): Contact details.
- Relationships: Links to tbl_claim (one adjuster handles many claims).
tbl_document
- Description: Stores documents submitted with claims (e.g., receipts, photos).
- Fields:
- document_id (INT, Primary Key): Unique identifier.
- claim_id (INT, Foreign Key): Links to tbl_claim.
- document_type (VARCHAR): Type (e.g., invoice, photo).
- file_path (VARCHAR): Storage location.
- Relationships: Links to tbl_claim.
tbl_payout
- Description: Tracks payouts made for approved claims.
- Fields:
- payout_id (INT, Primary Key): Unique identifier.
- claim_id (INT, Foreign Key): Links to tbl_claim.
- amount (DECIMAL): Payout amount.
- payout_date (DATE): Date of payout.
- Relationships: Links to tbl_claim.
tbl_insurance_product
- Description: Stores types of insurance products offered.
- Fields:
- product_id (INT, Primary Key): Unique identifier.
- name (VARCHAR): Product name (e.g., auto insurance).
- description (TEXT): Product details.
- Relationships: Links to tbl_policy (one product has many policies).
tbl_audit_log
- Description: Logs changes for compliance and auditing.
- Fields:
- log_id (INT, Primary Key): Unique identifier.
- table_name (VARCHAR): Table affected.
- action (VARCHAR): Action (e.g., insert, update).
- log_date (DATETIME): Timestamp.
- Relationships: No direct relationships; used for auditing.
tbl_claim_note
- Description: Stores notes added by adjusters during claim reviews.
- Fields:
- note_id (INT, Primary Key): Unique identifier.
- claim_id (INT, Foreign Key): Links to tbl_claim.
- adjuster_id (INT, Foreign Key): Links to tbl_adjuster.
- note_text (TEXT): Note content.
- note_date (DATETIME): Timestamp.
- Relationships: Links to tbl_claim and tbl_adjuster.
tbl_notification
- Description: Tracks notifications sent to policyholders (e.g., claim status updates).
- Fields:
- notification_id (INT, Primary Key): Unique identifier.
- policyholder_id (INT, Foreign Key): Links to tbl_policyholder.
- claim_id (INT, Foreign Key): Links to tbl_claim.
- message (TEXT): Notification content.
- sent_date (DATETIME): Timestamp.
- Relationships: Links to tbl_policyholder and tbl_claim.
SQL Create Statements
CREATE TABLE tbl_policyholder ( policyholder_id INT PRIMARY KEY, name VARCHAR(100), contact_info VARCHAR(255), address VARCHAR(255) ); CREATE TABLE tbl_insurance_product ( product_id INT PRIMARY KEY, name VARCHAR(100), description TEXT ); CREATE TABLE tbl_policy ( policy_id INT PRIMARY KEY, policyholder_id INT, product_id INT, policy_type VARCHAR(50), start_date DATE, end_date DATE, FOREIGN KEY (policyholder_id) REFERENCES tbl_policyholder(policyholder_id), FOREIGN KEY (product_id) REFERENCES tbl_insurance_product(product_id) ); CREATE TABLE tbl_claim ( claim_id INT PRIMARY KEY, policy_id INT, claim_date DATE, claim_amount DECIMAL(10,2), status VARCHAR(50), FOREIGN KEY (policy_id) REFERENCES tbl_policy(policy_id) ); CREATE TABLE tbl_adjuster ( adjuster_id INT PRIMARY KEY, name VARCHAR(100), contact_info VARCHAR(255) ); CREATE TABLE tbl_document ( document_id INT PRIMARY KEY, claim_id INT, document_type VARCHAR(50), file_path VARCHAR(255), FOREIGN KEY (claim_id) REFERENCES tbl_claim(claim_id) ); CREATE TABLE tbl_payout ( payout_id INT PRIMARY KEY, claim_id INT, amount DECIMAL(10,2), payout_date DATE, FOREIGN KEY (claim_id) REFERENCES tbl_claim(claim_id) ); CREATE TABLE tbl_audit_log ( log_id INT PRIMARY KEY, table_name VARCHAR(50), action VARCHAR(50), log_date DATETIME ); CREATE TABLE tbl_claim_note ( note_id INT PRIMARY KEY, claim_id INT, adjuster_id INT, note_text TEXT, note_date DATETIME, FOREIGN KEY (claim_id) REFERENCES tbl_claim(claim_id), FOREIGN KEY (adjuster_id) REFERENCES tbl_adjuster(adjuster_id) ); CREATE TABLE tbl_notification ( notification_id INT PRIMARY KEY, policyholder_id INT, claim_id INT, message TEXT, sent_date DATETIME, FOREIGN KEY (policyholder_id) REFERENCES tbl_policyholder(policyholder_id), FOREIGN KEY (claim_id) REFERENCES tbl_claim(claim_id) );
Explanation: This query joins multiple tables to list payouts within a specified year (2025), including claim details, policyholder names, and insurance product types. It’s useful for financial teams analyzing payout trends or regulators verifying compliance.
Additional Use Cases:
- Document Retrieval: Query tbl_document to fetch all documents for a claim, aiding adjuster reviews.
- Adjuster Workload: Query tbl_claim and tbl_claim_note to track claims assigned to an adjuster.
- Audit Trail: Query tbl_audit_log to review changes for compliance, such as claim status updates.
- Notification Log: Query tbl_notification to analyze communication history with policyholders.
These queries showcase how the database supports real-time claim tracking, financial reporting, and compliance, ensuring efficiency and transparency for all stakeholders.
Summary and Conclusion
This blog post explored the database design for the Insurance Claim Processing System, a solution that streamlines the complex process of handling insurance claims. We discussed the real-world problem it solves—inefficient, error-prone claim processing—and its importance for insurance companies, adjusters, policyholders, and regulators. The post highlighted why a well-structured database is essential, emphasizing data integrity, scalability, performance, and maintainability. Without proper design, issues like data redundancy or slow queries could delay claims and erode trust.
We outlined the steps to plan the database, from requirement analysis to stakeholder validation, ensuring the schema meets the system’s needs. The design includes 10 tables—such as tbl_policyholder, tbl_policy, tbl_claim, and tbl_payout—with fields, keys, and relationships to manage claims efficiently. SQL CREATE TABLE statements were provided to implement the schema, and example queries demonstrated practical applications, like generating claim status or payout reports, showcasing real-world functionality.
The value of this design lies in its ability to deliver efficiency and transparency. For policyholders, it provides real-time claim tracking, while adjusters benefit from streamlined workflows. Insurance companies reduce processing times, and regulators can audit compliance via audit logs. The normalized schema minimizes redundancy, while indexes optimize performance, making the system scalable for high claim volumes. Features like document management and notifications enhance user experience and accountability.
Readers are encouraged to apply this design process to similar systems, such as customer service platforms or financial tracking tools. As a next step, implement the SQL schema in a database like MySQL or PostgreSQL to test its functionality. Building a prototype app with a user interface for claim submission or tracking could bring the system to life. Explore related topics like database security or workflow automation to deepen your understanding.
This design process ensures a robust foundation for insurance claim processing, balancing efficiency, security, and scalability. Check out our other posts on database optimization or download the ER diagram for this system from our resources page (link placeholder). Let’s build systems that make insurance claims fast, fair, and transparent!
You may visit our Facebook page for more information, inquiries, and comments. Please subscribe also to our YouTube Channel to receive free capstone projects resources and computer programming tutorials.
Hire our team to do the project.