Urban Green Space Analysis Database Design
Introduction
Table of Contents
The Urban Green Space Analysis System is a powerful tool designed to support the planning, management, and evaluation of green spaces in urban environments. As cities grow, the demand for accessible parks, community gardens, and green corridors increases, yet urban planners often lack comprehensive data to optimize these spaces for environmental, social, and health benefits. This system addresses this real-world problem by collecting and analyzing data on green spaces, including their size, usage, biodiversity, and maintenance needs, to inform sustainable urban development. For example, city officials can use the system to identify underserved areas needing more parks or to assess the ecological impact of existing green spaces.
The target users include urban planners, municipal governments, environmental NGOs, researchers, and community organizations. Urban planners can leverage the system to prioritize green space development, while NGOs can track biodiversity or advocate for equitable access. Community groups might use it to monitor maintenance schedules or propose new green initiatives. Researchers can analyze usage patterns to study the impact of green spaces on mental health or air quality.
This blog post aims to guide readers through designing a database for the Urban Green Space Analysis System. You’ll learn how to model a database that supports data collection, analysis, and reporting for urban green spaces. We’ll cover the importance of a well-structured database, outline the planning process, detail the schema with tables and relationships, and provide SQL queries for practical operations. Whether you’re a developer building a civic tech solution, a student working on a capstone project, or a city official exploring data-driven planning, this post offers a clear blueprint to create a robust database. Expect to dive into entity-relationship modeling, normalization, and SQL implementations that ensure efficiency and scalability. By the end, you’ll have the tools to design a database that empowers sustainable urban planning and enhances community well-being.
The database design process we’ll cover addresses challenges like managing diverse data types, ensuring scalability for large cities, and supporting real-time analysis. From defining entities like green spaces and maintenance schedules to crafting queries for usage reports, this post equips you with practical insights to build a system that promotes greener, healthier cities. Let’s get started on designing a database for urban green space analysis!
Importance and Benefits of Database Design
A well-designed database is the foundation of the Urban Green Space Analysis System, enabling efficient data management, analysis, and reporting. Without a robust database, the system would struggle to handle the complex data needed to monitor and optimize urban green spaces, leading to inefficiencies and missed opportunities for sustainable planning.
Data Integrity: Accurate data is critical for reliable analysis. For example, linking a park’s maintenance records to its location ensures planners can track upkeep accurately. A poorly designed database risks inconsistencies, such as mismatched usage data or duplicate green space records, which could skew reports or mislead decision-making. By using primary and foreign keys, the database enforces relationships, ensuring data accuracy across entities like green spaces and biodiversity metrics.
Scalability: Cities vary in size, and the database must handle data from thousands of green spaces in large urban areas. A well-structured schema, with indexed fields like green space IDs or location coordinates, supports rapid data retrieval as datasets grow. This ensures the system remains responsive when analyzing sprawling park networks or expanding to new cities.
Performance: Efficient database design optimizes operations like generating usage reports or assessing biodiversity. Without proper indexing or normalization, queries could slow down, delaying insights for planners. For instance, a query to identify underutilized parks needs quick results to inform budget decisions. A streamlined schema minimizes query execution time, enhancing user experience.
Maintainability: The system must adapt to new requirements, such as tracking new environmental metrics or integrating community feedback. A modular database, with clearly defined tables and relationships, simplifies updates without disrupting operations. This reduces maintenance costs and ensures long-term reliability.
Challenges Without Proper Design: Without a solid database, the system could face data redundancy, where green space or maintenance details are duplicated, wasting storage and risking inconsistencies. For example, duplicate park records could lead to conflicting usage data. Slow queries due to unnormalized data could delay reports, hindering timely planning. Security risks, such as unauthorized access to sensitive data like community feedback or environmental reports, could arise without proper access controls enforced through the database.
By prioritizing database design, the Urban Green Space Analysis System ensures efficient operations, avoids redundancy, supports growth, and provides secure, reliable access to data. This foundation enables data-driven urban planning, fostering greener, healthier cities.
Steps in Planning the Database
Designing a database for the Urban Green Space Analysis System requires a structured approach to meet its unique needs. Below are the key steps, tailored to ensure effective data management for urban green spaces.
Step 1: Requirement Analysis
Begin by gathering requirements from stakeholders—urban planners, municipalities, NGOs, and community groups. The system must track green space details, usage, biodiversity, and maintenance, while supporting reports for planning and advocacy. For example, planners need data on park accessibility, while NGOs require biodiversity metrics. This step identifies functional needs (e.g., usage tracking) and non-functional needs (e.g., scalability and security).
Step 2: Entity and Attribute Identification
Identify core entities and their attributes. Entities include GreenSpaces, Locations, UsageRecords, Biodiversity, and MaintenanceSchedules. Attributes for GreenSpaces might include greenspace_id, name, and size. UsageRecords need attributes like usage_id, greenspace_id, and visitor_count. This ensures all data points are captured for analysis and reporting.
Step 3: Relationship Mapping
Define how entities relate. For example, a GreenSpace is linked to a Location, and each GreenSpace has multiple UsageRecords and MaintenanceSchedules. Biodiversity data is tied to GreenSpaces. Mapping these relationships ensures the database reflects real-world interactions, such as linking maintenance tasks to specific parks.
Step 4: Normalization
Normalize the database to eliminate redundancy and ensure data integrity. For example, store location details in a separate table rather than repeating them in GreenSpaces. This reduces storage needs and simplifies updates, such as when a park’s address changes. Normalization ensures accurate linkages, like connecting usage data to specific green spaces.
Step 5: Drafting an ER Diagram
Create an Entity-Relationship (ER) Diagram to visualize entities, attributes, and relationships. The ER diagram would show GreenSpaces linked to Locations, UsageRecords, Biodiversity, and MaintenanceSchedules. This serves as a blueprint for developers and helps stakeholders validate the design.
Step 6: Validating with Stakeholders
Share the ER diagram and schema with stakeholders to ensure it meets their needs. For example, planners might confirm that GreenSpaces includes accessibility metrics, while NGOs verify biodiversity tracking. Community groups might ensure feedback mechanisms are supported. Iterative feedback aligns the design with real-world use cases like planning or advocacy.
By following these steps, the Urban Green Space Analysis System’s database is tailored to manage green space data efficiently, ensuring scalability and supporting data-driven urban planning.
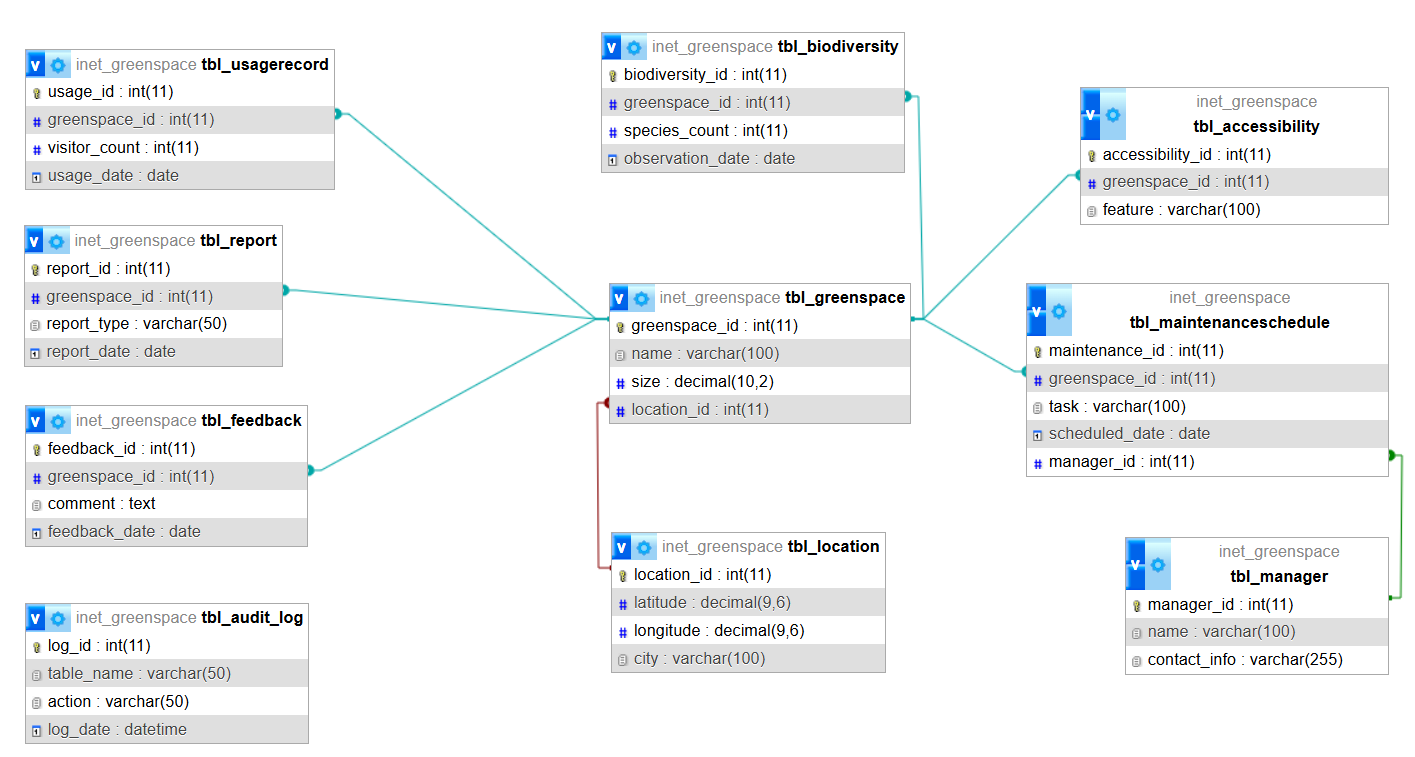
Database Design: List of Tables
The Urban Green Space Analysis System requires a comprehensive database schema to manage green space data. Below is a list of 10 key tables, each with a description, fields, primary and foreign keys, and relationships. SQL CREATE TABLE statements are provided to implement the schema.
tbl_greenspace
- Description: Stores details about urban green spaces (e.g., parks, gardens).
- Fields:
- greenspace_id (INT, Primary Key): Unique identifier.
- name (VARCHAR): Green space name.
- size (DECIMAL): Area in hectares.
- location_id (INT, Foreign Key): Links to tbl_location.
- Relationships: Links to tbl_location, tbl_usagerecord, tbl_biodiversity, and tbl_maintenanceschedule.
tbl_location
- Description: Stores geographical details of green spaces.
- Fields:
- location_id (INT, Primary Key): Unique identifier.
- latitude (DECIMAL): Latitude coordinate.
- longitude (DECIMAL): Longitude coordinate.
- city (VARCHAR): City name.
- Relationships: Links to tbl_greenspace (one location has many green spaces).
tbl_usagerecord
- Description: Tracks visitor usage of green spaces.
- Fields:
- usage_id (INT, Primary Key): Unique identifier.
- greenspace_id (INT, Foreign Key): Links to tbl_greenspace.
- visitor_count (INT): Number of visitors.
- usage_date (DATE): Date of record.
- Relationships: Links to tbl_greenspace.
tbl_biodiversity
- Description: Stores biodiversity metrics for green spaces.
- Fields:
- biodiversity_id (INT, Primary Key): Unique identifier.
- greenspace_id (INT, Foreign Key): Links to tbl_greenspace.
- species_count (INT): Number of species.
- observation_date (DATE): Date of observation.
- Relationships: Links to tbl_greenspace.
tbl_maintenanceschedule
- Description: Tracks maintenance tasks for green spaces.
- Fields:
- maintenance_id (INT, Primary Key): Unique identifier.
- greenspace_id (INT, Foreign Key): Links to tbl_greenspace.
- task (VARCHAR): Task description (e.g., mowing).
- scheduled_date (DATE): Scheduled date.
- Relationships: Links to tbl_greenspace.
tbl_manager
- Description: Stores details about green space managers.
- Fields:
- manager_id (INT, Primary Key): Unique identifier.
- name (VARCHAR): Manager’s name.
- contact_info (VARCHAR): Contact details.
- Relationships: Links to tbl_maintenanceschedule (one manager oversees many tasks).
tbl_feedback
- Description: Stores community feedback on green spaces.
- Fields:
- feedback_id (INT, Primary Key): Unique identifier.
- greenspace_id (INT, Foreign Key): Links to tbl_greenspace.
- comment (TEXT): Feedback text.
- feedback_date (DATE): Date submitted.
- Relationships: Links to tbl_greenspace.
tbl_accessibility
- Description: Stores accessibility features of green spaces.
- Fields:
- accessibility_id (INT, Primary Key): Unique identifier.
- greenspace_id (INT, Foreign Key): Links to tbl_greenspace.
- feature (VARCHAR): Feature (e.g., wheelchair access).
- Relationships: Links to tbl_greenspace.
tbl_audit_log
- Description: Logs changes for compliance and auditing.
- Fields:
- log_id (INT, Primary Key): Unique identifier.
- table_name (VARCHAR): Table affected.
- action (VARCHAR): Action (e.g., insert, update).
- log_date (DATETIME): Timestamp.
- Relationships: No direct relationships; used for auditing.
tbl_report
- Description: Stores generated reports for analysis.
- Fields:
- report_id (INT, Primary Key): Unique identifier.
- greenspace_id (INT, Foreign Key): Links to tbl_greenspace.
- report_type (VARCHAR): Type (e.g., usage, biodiversity).
- report_date (DATE): Date generated.
- Relationships: Links to tbl_greenspace.
SQL Create Statements:
-- Create tbl_location first (no dependencies) CREATE TABLE tbl_location ( location_id INT PRIMARY KEY, latitude DECIMAL(9,6), longitude DECIMAL(9,6), city VARCHAR(100) ); -- Create tbl_greenspace (depends on tbl_location) CREATE TABLE tbl_greenspace ( greenspace_id INT PRIMARY KEY, name VARCHAR(100), size DECIMAL(10,2), location_id INT, FOREIGN KEY (location_id) REFERENCES tbl_location(location_id) ); -- Create tbl_manager (no dependencies) CREATE TABLE tbl_manager ( manager_id INT PRIMARY KEY, name VARCHAR(100), contact_info VARCHAR(255) ); -- Create tbl_maintenanceschedule (depends on tbl_greenspace and tbl_manager) CREATE TABLE tbl_maintenanceschedule ( maintenance_id INT PRIMARY KEY, greenspace_id INT, task VARCHAR(100), scheduled_date DATE, manager_id INT, FOREIGN KEY (greenspace_id) REFERENCES tbl_greenspace(greenspace_id), FOREIGN KEY (manager_id) REFERENCES tbl_manager(manager_id) ); -- Create remaining tables CREATE TABLE tbl_usagerecord ( usage_id INT PRIMARY KEY, greenspace_id INT, visitor_count INT, usage_date DATE, FOREIGN KEY (greenspace_id) REFERENCES tbl_greenspace(greenspace_id) ); CREATE TABLE tbl_biodiversity ( biodiversity_id INT PRIMARY KEY, greenspace_id INT, species_count INT, observation_date DATE, FOREIGN KEY (greenspace_id) REFERENCES tbl_greenspace(greenspace_id) ); CREATE TABLE tbl_feedback ( feedback_id INT PRIMARY KEY, greenspace_id INT, comment TEXT, feedback_date DATE, FOREIGN KEY (greenspace_id) REFERENCES tbl_greenspace(greenspace_id) ); CREATE TABLE tbl_accessibility ( accessibility_id INT PRIMARY KEY, greenspace_id INT, feature VARCHAR(100), FOREIGN KEY (greenspace_id) REFERENCES tbl_greenspace(greenspace_id) ); CREATE TABLE tbl_audit_log ( log_id INT PRIMARY KEY, table_name VARCHAR(50), action VARCHAR(50), log_date DATETIME ); CREATE TABLE tbl_report ( report_id INT PRIMARY KEY, greenspace_id INT, report_type VARCHAR(50), report_date DATE, FOREIGN KEY (greenspace_id) REFERENCES tbl_greenspace(greenspace_id) );
Explanation: This query joins tbl_biodiversity, tbl_greenspace, and tbl_location to list green spaces with biodiversity data from the past year, ordered by species count. It helps prioritize conservation efforts or research.
Additional Use Cases:
- Maintenance Tracking: Query tbl_maintenanceschedule to monitor upcoming tasks for a green space.
- Community Feedback Analysis: Query tbl_feedback to identify common concerns or suggestions for a park.
- Accessibility Report: Query tbl_accessibility to list green spaces with specific features like wheelchair access.
- Audit Trail: Query tbl_audit_log to track changes for compliance, such as updates to usage data.
These queries demonstrate how the database supports real-time analysis, planning, and community engagement, ensuring green spaces meet urban needs.
Summary and Conclusion
This blog post explored the database design for the Urban Green Space Analysis System, a solution that empowers data-driven management of urban parks and gardens. We discussed the real-world problem it solves—optimizing green spaces for sustainability and community well-being—and its relevance for urban planners, municipalities, NGOs, and community groups. The post highlighted why a well-structured database is critical, emphasizing data integrity, scalability, performance, and maintainability. Without proper design, issues like data redundancy or slow queries could hinder effective planning.
We outlined the steps to plan the database, from requirement analysis to stakeholder validation, ensuring the schema meets diverse needs. The design includes 10 tables—such as tbl_greenspace, tbl_location, tbl_usagerecord, and tbl_biodiversity—with fields, keys, and relationships to manage green space data. SQL CREATE TABLE statements were provided to implement the schema, and example queries demonstrated practical applications, like generating usage or biodiversity reports, showcasing real-world functionality.
The value of this design lies in its ability to support sustainable urban planning. For planners, it provides insights into park usage and accessibility, while NGOs benefit from biodiversity tracking. Community groups can leverage feedback data to advocate for improvements, and municipalities ensure efficient maintenance. The normalized schema minimizes redundancy, while indexes optimize performance, making the system scalable for large cities. Features like audit logs and report tracking enhance transparency and accountability.
Readers are encouraged to apply this design process to similar systems, such as environmental monitoring or community planning tools. As a next step, implement the SQL schema in a database like MySQL or PostgreSQL to test its functionality. Building a prototype app with a dashboard for visualizing usage or biodiversity data could bring the system to life. Explore related topics like geospatial database design or data analytics to deepen your understanding.
This design process ensures a robust foundation for urban green space analysis, balancing efficiency, scalability, and community impact. Check out our other posts on civic tech solutions or download the ER diagram for this system from our resources page (link placeholder). Let’s build systems that create greener, healthier cities!
You may visit our Facebook page for more information, inquiries, and comments. Please subscribe also to our YouTube Channel to receive free capstone projects resources and computer programming tutorials.
Hire our team to do the project.

